Establishing systems that specifically control electric power switches based on the practical implementation of Artificial Intelligence in everyday life reduces the likelihood of accidental switch activation and potentially increases security by ensuring it responds only to authorised users. Individuals with physical disabilities also require systems devoid of direct human interventions and physical interactions to control electrical and power switches. Existing methods for achieving these tasks include smart objects, the Internet of Things, and biometric technologies, with their attendant strengths and weaknesses. This paper presents the design of a voice signal framework for remote control of power switches. The framework uses a voice sensor connected to an Arduino microcontroller to amplify the volume of the user’s voice, while a voice sensor connected to a power switch relay is used to capture the voice signal for registration, training, verification and processing. The Arduino Nano 33 BLE Sense Rev 2 microcontroller sensor combines a tiny form factor with the capability to operate TinyML and TensorFlow Lite environment sensors while running at reconfigurable operating voltage. The switch relay regulates a high voltage to a minimum acceptable level based on integration with the Arduino microcontrollers. The framework also requires an external ESP8266/ESP32 Wi-Fi module to establish a connection between the microcontroller and the network as well as simple TCP/IP connections using Hayes-style commands. The system requires a power switch, an electromechanical device that uses the flow of electric current to open or close an electrical circuit. The user voice recognition is based on Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) networks. The combination of these two models guarantees an effective capturing of temporal dependencies in sequential data typical of audio signals.
| Published in | International Journal of Sensors and Sensor Networks (Volume 13, Issue 2) |
| DOI | 10.11648/j.ijssn.20251302.14 |
| Page(s) | 56-64 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Remote Control, Power Switch, Switch Control, Voice Recognition, Arduino Microcontroller
RNN | Recurrent Neural Network |
LSTM | Long Short-Term Memory |
SCTN | Spiking Continuous Time Neuron |
SNN | Spiking Neural Network |
RWCP | Real-World Computing Partnership |
SRS | Sounding Reference Signal |
VAD | Voice Activity Detection |
NLP | Natural Language Processing |
ANC | Active Noise Control |
WFSS | Wiener Filtering Spectral Subtraction |
MFCC | Mel-Frequency Cepstral Coefficient |
DCT | Discrete Cosine Transform |
STFT | Short-Time Fourier Transform |
TETFund | Tertiary Education Trust Fund |
| [1] |
Hambley A. (2025), Electrical Engineering,
https://easypdfs.cloud/downloads/4922968-Allan%20Hambley%20Electrical%20Engineering |
| [2] | Glover J. D., Thomas J. O., Mulukutla S. S. (2022), Power System Analysis and Design, Cengage Learning, 7th Edition. |
| [3] | Wang Z., Defang L., Yunan S., Xiaoyi P., Feng L., John C. S. L., and Kui R. (2022), A Survey on IoT-Enabled Home Automation Systems: Attacks and Defenses, IEEE Communications Surveys and Tutorials, 24(4). |
| [4] | Neha M., and Yogita B. (2017), Literature Review on Home Automation System, International Journal of Advanced Research in Computer and Communication Engineering, 6(3). |
| [5] | Wanzala J. N. and Atim M. R. (2024), Design and simulation of a smart master switch system based on multi-input XOR logic gate, Discover Electronics, 1: 23. |
| [6] | Subramaniam K., Husin S. H., Anas S. A. and A. H. Hamidon (2014), Multiple Method Switching System for Electrical Appliances using Programmable Logic Controller, WSEAS Transactions on Systems and Control, 4(6). |
| [7] | Sakshi S., Manish K. M., Nisha D. (2023), Home Automation System, International Journal of Novel Research and Development, 8(1); 96-100. |
| [8] | Abe B. C., Araromi H. O., Shokenu E. S., Idowu P. O., Babatunde J. D., Adeagbo M. O., Itanrin H. O. (2022), Biometric Access Control Using Voice and Fingerprint, Engineering and Technology Journal, 7(7). |
| [9] | Yadav H., Bansal U. (2021), A Novel Low-Voltage Low Power FGMOS and CMOS Resister Current Mirror. |
| [10] | Schafer R., and Rabiner L. (2011), Real-Time Digital Hardware Pitch Detector. IEEE Transactions on Acoustics, Speech, and Signal Processing, 24(1), 2-8. |
| [11] | Yang C. H., Gu Y., Liu Y. C., Ghosh S., Bulyko I., Stolcke A. (2023), Generative speech recognition error correction with large language models and task-activating prompting, in: 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), IEEE, 1-8. |
| [12] | Al-Ogaili A., Ramasamy A., Juhana T., Tengku H., Al-Masri A., Hoon Y., Jebur M., Verayiah R., Marsadek M. (2020). Estimation of the Energy Consumption of Battery-Driven Electric Buses by Integrating Digital Elevation and Longitudinal Dynamic Models: Malaysia as a Case Study. Applied Energy. 280. |
| [13] | Bensimon, M., Greenberg, S., and Haiut, M. (2021). Using a Low-Power Spiking Continuous Time Neuron (SCTN) for Sound Signal Processing. Sensors, 21(4), 1065. |
| [14] | Wang B. (2021), Power Control Apparatus and Method, and Electronic Device. |
| [15] | Maral F., Hamidreza R., Nassim R. and Hamed A. (2023). Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling, Electronics, 12(4): 795. |
| [16] | Amannah C. I. and Nlerum P. (2022). Voice-Based Automation Control Platform for Home Electrical Devices, Available: |
| [17] | Junji A., Satoshi A., Takahiro Y. and Kenichi, K. (2022). Voice Control Device and Voice Control System. |
| [18] | Iliev, Y., and Ilieva, G. (2023). A Framework for Smart Home System with Voice Control Using NLP Methods. Electronics, 12(1), 116. |
| [19] | Dongyuan S., Bhan L. and Woon-Seng G., (2023). Active Noise Control in the New Century: The Role and Prospect of Signal Processing, Internoise, Available: |
| [20] | Samia D. S. M., Bessa E., Blumstein D. T., Nunes J. A. C. C., Azzurro E., Morroni L., Sbragaglia V., Januchowski-Hartley F. A., and Geffroy B. (2019). A Meta-Analysis of Fish Behavioural Reaction to Underwater Human Presence. Fish and Fisheries, 20, 817-829. |
| [21] | Hajiaghayi M., Vahedi E. (2019). Code Failure Prediction and Pattern Extraction Using LSTM Networks. 55-62. |
| [22] | Graves A., Mohamed A. R., and Hinton, G. (2013), Speech Recognition with Deep Recurrent Neural Networks. 2013, Available: |
| [23] | Srivastava N., Hinton G., Krizhevsky A., Sutskever I., and Salakhutdinov R. (2014), Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Journal of Machine Learning Research 15, 1929-1958. |
| [24] | Kingma, D. P., and Ba, J. (2014). Adam: A Method for Stochastic Optimization. CoRR, abs/1412.6980. |
| [25] | Yuliy I. and Galina I. (2022). A Framework for Smart Home System with Voice Control Using NLP Methods, Electronics 2023, 12(1), 116; |
APA Style
Remi-Ofakunrin, B. O., Iwasokun, G. B., Atajeromavwo, E. J., Akinyede, R. O., Alowolodu, O., et al. (2025). Design of a Framework for Switch Power Control Using Voice Signal. International Journal of Sensors and Sensor Networks, 13(2), 56-64. https://doi.org/10.11648/j.ijssn.20251302.14
ACS Style
Remi-Ofakunrin, B. O.; Iwasokun, G. B.; Atajeromavwo, E. J.; Akinyede, R. O.; Alowolodu, O., et al. Design of a Framework for Switch Power Control Using Voice Signal. Int. J. Sens. Sens. Netw. 2025, 13(2), 56-64. doi: 10.11648/j.ijssn.20251302.14
AMA Style
Remi-Ofakunrin BO, Iwasokun GB, Atajeromavwo EJ, Akinyede RO, Alowolodu O, et al. Design of a Framework for Switch Power Control Using Voice Signal. Int J Sens Sens Netw. 2025;13(2):56-64. doi: 10.11648/j.ijssn.20251302.14
@article{10.11648/j.ijssn.20251302.14,
author = {Blossom Oluwakorede Remi-Ofakunrin and Gabriel Babatunde Iwasokun and Edafe John Atajeromavwo and Raphael Olufemi Akinyede and Olufunso Alowolodu and Samuel Oluwatayo Ogunlana and David Bamidele Adewole and Ednah Olubunmi Aliyu},
title = {Design of a Framework for Switch Power Control Using Voice Signal
},
journal = {International Journal of Sensors and Sensor Networks},
volume = {13},
number = {2},
pages = {56-64},
doi = {10.11648/j.ijssn.20251302.14},
url = {https://doi.org/10.11648/j.ijssn.20251302.14},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijssn.20251302.14},
abstract = {Establishing systems that specifically control electric power switches based on the practical implementation of Artificial Intelligence in everyday life reduces the likelihood of accidental switch activation and potentially increases security by ensuring it responds only to authorised users. Individuals with physical disabilities also require systems devoid of direct human interventions and physical interactions to control electrical and power switches. Existing methods for achieving these tasks include smart objects, the Internet of Things, and biometric technologies, with their attendant strengths and weaknesses. This paper presents the design of a voice signal framework for remote control of power switches. The framework uses a voice sensor connected to an Arduino microcontroller to amplify the volume of the user’s voice, while a voice sensor connected to a power switch relay is used to capture the voice signal for registration, training, verification and processing. The Arduino Nano 33 BLE Sense Rev 2 microcontroller sensor combines a tiny form factor with the capability to operate TinyML and TensorFlow Lite environment sensors while running at reconfigurable operating voltage. The switch relay regulates a high voltage to a minimum acceptable level based on integration with the Arduino microcontrollers. The framework also requires an external ESP8266/ESP32 Wi-Fi module to establish a connection between the microcontroller and the network as well as simple TCP/IP connections using Hayes-style commands. The system requires a power switch, an electromechanical device that uses the flow of electric current to open or close an electrical circuit. The user voice recognition is based on Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) networks. The combination of these two models guarantees an effective capturing of temporal dependencies in sequential data typical of audio signals.},
year = {2025}
}
TY - JOUR T1 - Design of a Framework for Switch Power Control Using Voice Signal AU - Blossom Oluwakorede Remi-Ofakunrin AU - Gabriel Babatunde Iwasokun AU - Edafe John Atajeromavwo AU - Raphael Olufemi Akinyede AU - Olufunso Alowolodu AU - Samuel Oluwatayo Ogunlana AU - David Bamidele Adewole AU - Ednah Olubunmi Aliyu Y1 - 2025/11/22 PY - 2025 N1 - https://doi.org/10.11648/j.ijssn.20251302.14 DO - 10.11648/j.ijssn.20251302.14 T2 - International Journal of Sensors and Sensor Networks JF - International Journal of Sensors and Sensor Networks JO - International Journal of Sensors and Sensor Networks SP - 56 EP - 64 PB - Science Publishing Group SN - 2329-1788 UR - https://doi.org/10.11648/j.ijssn.20251302.14 AB - Establishing systems that specifically control electric power switches based on the practical implementation of Artificial Intelligence in everyday life reduces the likelihood of accidental switch activation and potentially increases security by ensuring it responds only to authorised users. Individuals with physical disabilities also require systems devoid of direct human interventions and physical interactions to control electrical and power switches. Existing methods for achieving these tasks include smart objects, the Internet of Things, and biometric technologies, with their attendant strengths and weaknesses. This paper presents the design of a voice signal framework for remote control of power switches. The framework uses a voice sensor connected to an Arduino microcontroller to amplify the volume of the user’s voice, while a voice sensor connected to a power switch relay is used to capture the voice signal for registration, training, verification and processing. The Arduino Nano 33 BLE Sense Rev 2 microcontroller sensor combines a tiny form factor with the capability to operate TinyML and TensorFlow Lite environment sensors while running at reconfigurable operating voltage. The switch relay regulates a high voltage to a minimum acceptable level based on integration with the Arduino microcontrollers. The framework also requires an external ESP8266/ESP32 Wi-Fi module to establish a connection between the microcontroller and the network as well as simple TCP/IP connections using Hayes-style commands. The system requires a power switch, an electromechanical device that uses the flow of electric current to open or close an electrical circuit. The user voice recognition is based on Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) networks. The combination of these two models guarantees an effective capturing of temporal dependencies in sequential data typical of audio signals. VL - 13 IS - 2 ER -
Department of Computer Science, Federal University of Technology, Akure, Nigeria
Research Fields: Signal processing, biometric authentication, system security
Department of Software Engineering, Federal University of Technology, Akure, Nigeria
Research Fields: Software engineering, artificial intelligence, signal processing
Department of Data Science, Delta State University, Abraka, Nigeria
Research Fields: Artificial intelligence
Department of Information Systems, Federal University of Technology, Akure, Nigeria
Research Fields: System security, cybersecurity, cloud computing
Department of Cybersecurity, Federal University of Technology, Akure, Nigeria
Research Fields: Cybersecurity, cloud computing
Department of Computer Science, Adekunle Ajasin University, Akungba-Akoko, Nigeria
Research Fields: biometric security, signal processing
Department of Software Engineering, Federal University of Technology, Akure, Nigeria
Research Fields: software engineering, artificial intelligence.
Department of Computer Science, Adekunle Ajasin University, Akungba-Akoko, Nigeria
Research Fields: Soft computing
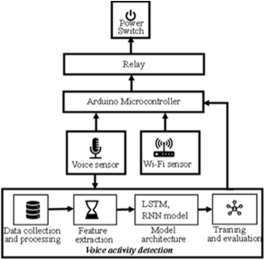
Figure 1. Architecture of the proposed system.

Figure 2. Microphone-fitted voice sensor.

Figure 3. Arduino Nano 33 BLE sense Rev 2.

Figure 4. A Relay.

Figure 5. Wi-Fi module.
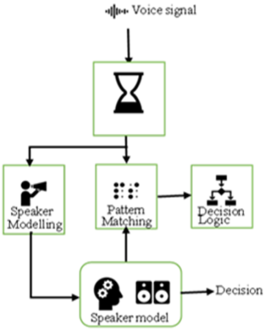
Figure 6. Voice recognition structure.
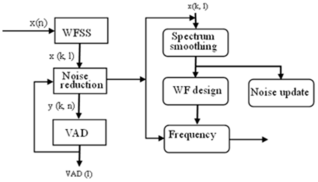
Figure 7. Block diagram of the denoising process.
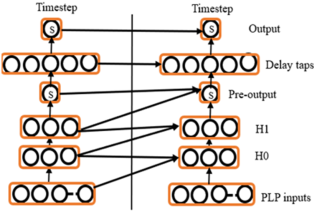
Figure 8. Feed-forward NN architecture with recurrence added at various points.
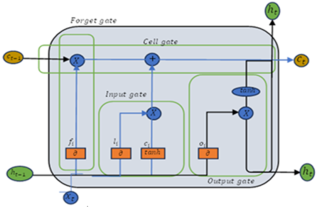
Figure 9. The LSTM architecture.
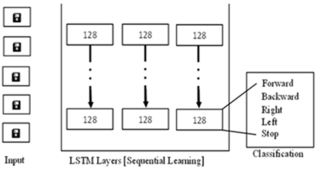
Figure 10. Architecture of LSTM for speech recognition.
Information

